- Entrainer un modèle de Machine Learning
- Pourquoi entrainer ?
- Comment entrainer ?
- Ouvrir le Dataset
- Ouvrir CreateML
- Validation Data
- Training Data
- Nettoyer notre dataset
- Lancer l’entrainement
- Résultats
- Tester notre modèle
- Exporter notre modèle
#Entrainer un modèle de Machine Learning
#Pourquoi entrainer ?
Lorsque l’on veut utiliser un modèle de Machine Learning, il faut d’abord l’entrainer. Cela permet de lui apprendre à faire une tâche spécifique.
Par exemple, si l’on veut entrainer un modèle pour qu’il reconnaisse des images de chats, il faut lui donner des images de chats et des images qui ne sont pas des chats.
#Comment entrainer ?
Pour cet exercice je vous ai déjà fait télécharger ce qu’on appel un dataset, c’est un ensemble de données qui vont nous servir à entrainer notre modèle.
Le plus long dans un projet de Machine Learning est de trouver un bon dataset, il faut qu’il soit assez grand pour que le modèle puisse apprendre, mais pas trop grand pour que l’entrainement ne prenne pas trop de temps, et surtout qu’il soit de bonne qualité :
- Correctement etiquetté
- Dans notre langue
- Et au bon format
Bon il s’avère que c’est rarement le cas.
#Ouvrir le Dataset
Ouvrez maintenant le fichier .csv que vous avez téléchargé précédemment.

Les colonnes qui vont nous intéresser sont les colonnes tweet_text et sentiment.
On appelle tweet_text le texte que nous voulons analyser, et sentiment le “Label”.
En machine Learning, le label est la donnée que l’on veut prédire, c’est à dire que l’on veut que notre modèle nous donne.
Par exemple :
| tweet_text | sentiment |
|---|---|
| Je suis content | Positif |
| Je suis triste | Négatif |
| Je suis fatigué | Neutre |
| Je suis content et triste | Mixed |
En donnant à notre réseau de neurones suffisamment de phrase d’exemple avec des sentiments associés, il va pouvoir apprendre à reconnaitre les sentiments lorsqu’on lui donne une nouvelle phrase.
Aller, à nous de jouer !
#Ouvrir CreateML
Maintenant ouvrez CreateML et créer un projet de type “Text Classifier” et choisissez le dataset que vous avez téléchargé.
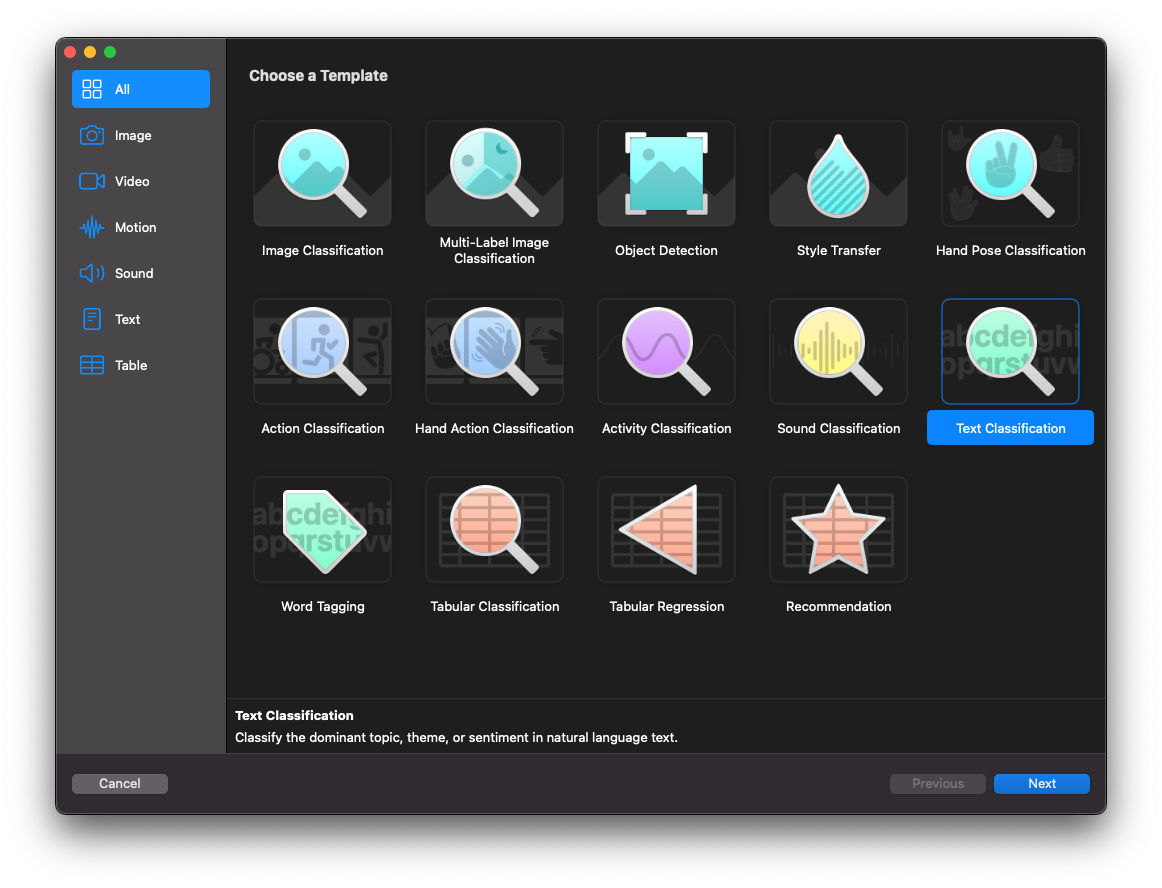
Nommez le projet “SentimentAnalysis” et cliquez sur “Next”.
Vous devriez tomber sur l’interface suivante :
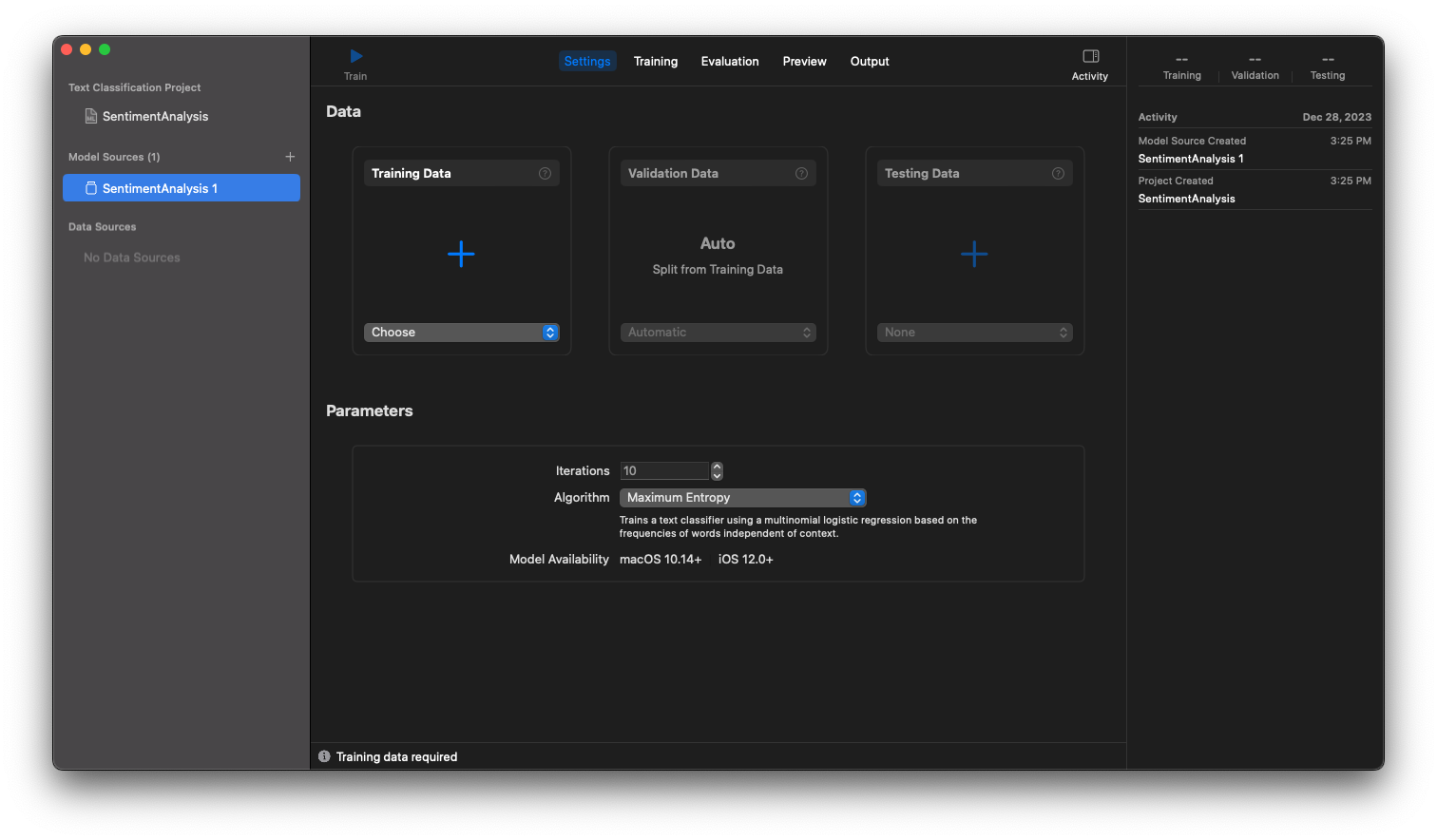
Le logiciel nous demande plusieurs choses :
| Nom | Description |
|---|---|
| Training Data | Les données qui vont servir à entrainer notre modèle |
| Validation Data | Les données qui vont servir à valider notre modèle |
| Test Data | Les données qui vont servir à tester notre modèle |
#Validation Data
La validation data est une partie du dataset qui va servir à valider notre modèle, c’est à dire à vérifier qu’il fonctionne bien.
Tout au long de l’entrainement CreateML va tester notre modèle avec la validation data et nous donner un score de précision, son objectif est d’avoir une précision élevé, sans pour autant trop fit notre modèle.
Notre modèle doit garder une part d’incertitude pour pouvoir généraliser et ne pas être trop spécifique à notre dataset.
#Training Data
Ajoutons nos données d’entrainement, si vous le faite maintenant, vous verrez que cela ne fonctionnera pas. En effet CreateML ne sais pas encore comment lire notre dataset.
Nous devons respecter un formalisme, notamment sur le nom des colonnes. Modifions le dataset pour que cela fonctionne, qui nous est expliqué quand on clique sur ?.
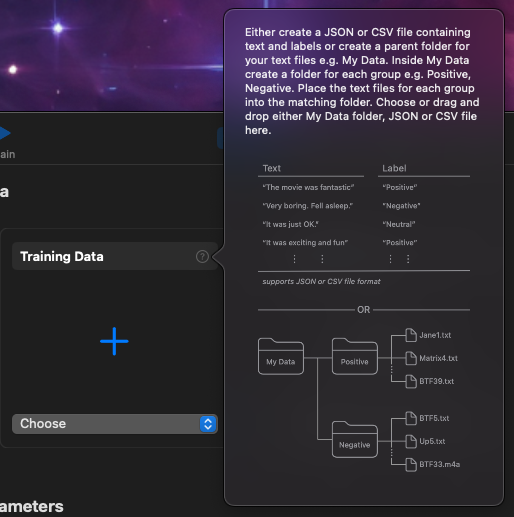
Le logiciel attend donc une colonne Text et une colonne Label.
#Nettoyer notre dataset
Modifiez le .csv pour que cela fonctionne.
Le fun commence ici, car modifier un CSV peut paraitre simple, sauf que si vous utilisez Excel ou Numbers en français, ils risquent de modifier le séparateur de colonne qui est une virgule
,par un point virgule;et donc le rendre illisible par CreateML.
Vous pouvez utiliser Visual Studio Code pour modifier le fichier, ou TableTool sur Mac.
💁♂️ Si vraiment vous n’y arrivez pas, vous pouvez 📄 télécharger le fichier modifié ici
Tout fonctionne si vous avez ce genre d’interface après importation du CSV :

#Lancer l’entrainement
Vérifiez les paramètres d’entrainement ici, puis lancer l’entrainement en cliquant sur “Train”.
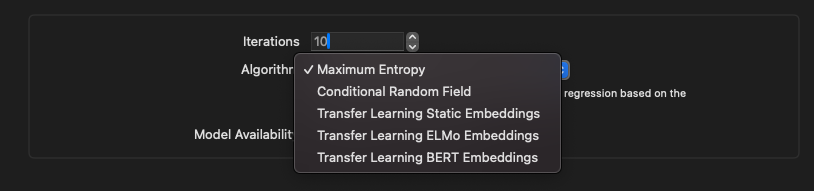
Ces paramètres permettent de régler le nombre d’itérations, souvenez vous que plus il y a d’itérations, plus l’entrainement sera long, mais plus le modèle sera précis, mais trop d’itérations peut aussi faire
overfitle modèle et donc le rendre moins généraliste, c’est à dire qu’il ne saura pas reconnaitre des phrases qui ne sont pas dans le dataset.
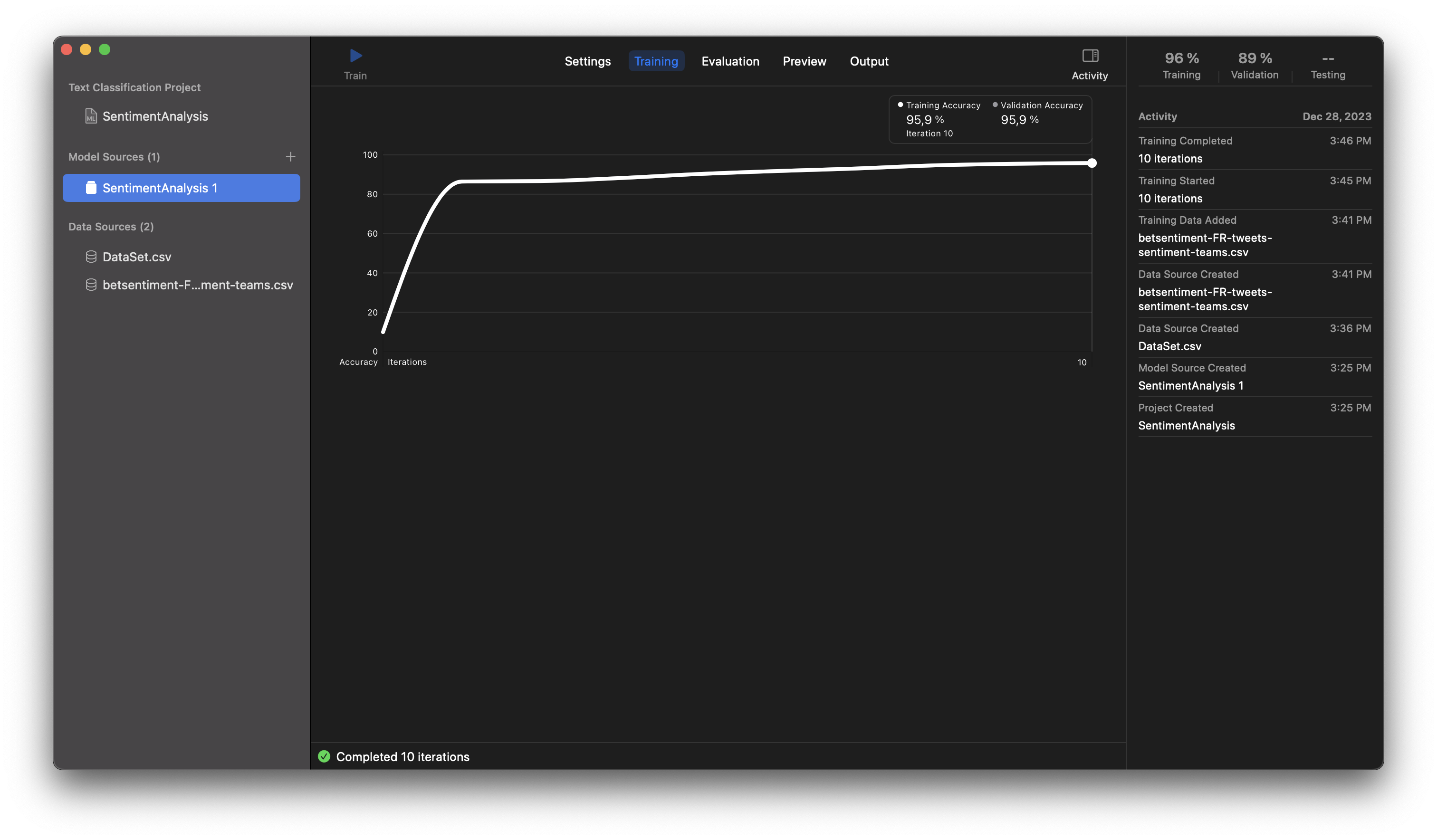
#Résultats
Vous devriez avoir un écran qui s’affiche avec les résultats de l’entrainement.
#Tester notre modèle
Une fois cette étape terminé, vous pouvez tester rapidement votre modèle en cliquant sur “Preview” en haut de la fenêtre.
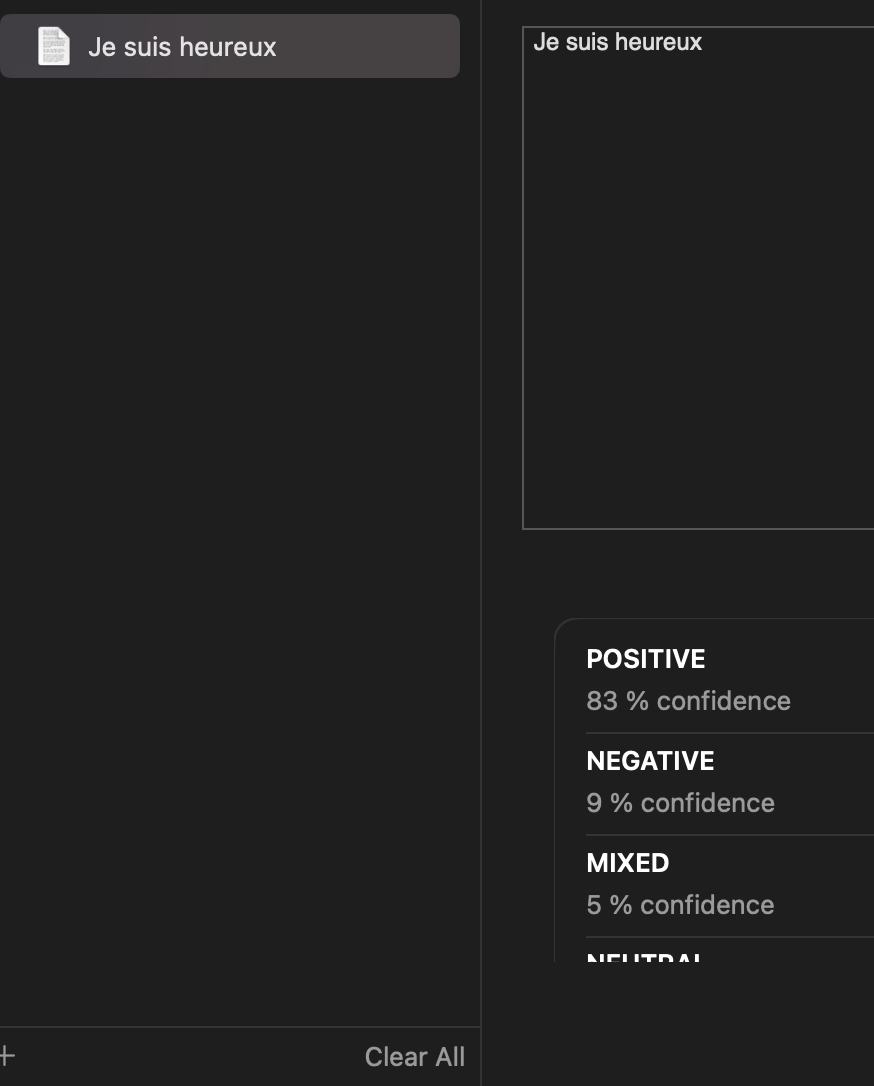
Amusez vous à tester quelques phrases, vous verrez que le modèle n’est pas parfait, mais il fonctionne plutôt bien.
#Exporter notre modèle
Allez dans “Output” et cliquez sur “Get”.
Enregistrez le modèle dans le dossier de votre projet, nous allons l’utiliser dans notre application.
💁♂️ Si jamais vous n’avez pas pu entrainer le réseau, vous pouvez 📄 télécharger le modèle déjà entrainé ici